
Markets Are Efficient, Information Is Perfect, and AI Will Turbocharge Profitability
Or not.
For decades, the comforting story went like this:
markets are efficient, information is rapidly reflected in prices, and any remaining frictions will be shaved away by technology.
In that story, AI is the final boss of efficiency.
It reads faster than any analyst, digests more documents than any back office, and never gets tired.
Give it a few more years, and we’ll have:
- Flawless OCR on every credit agreement and covenant schedule.
- Instant extraction of every term into pristine databases.
- Perfectly informed lending, securitization, valuation, and trading.
What could possibly go wrong?
Our hypothesis
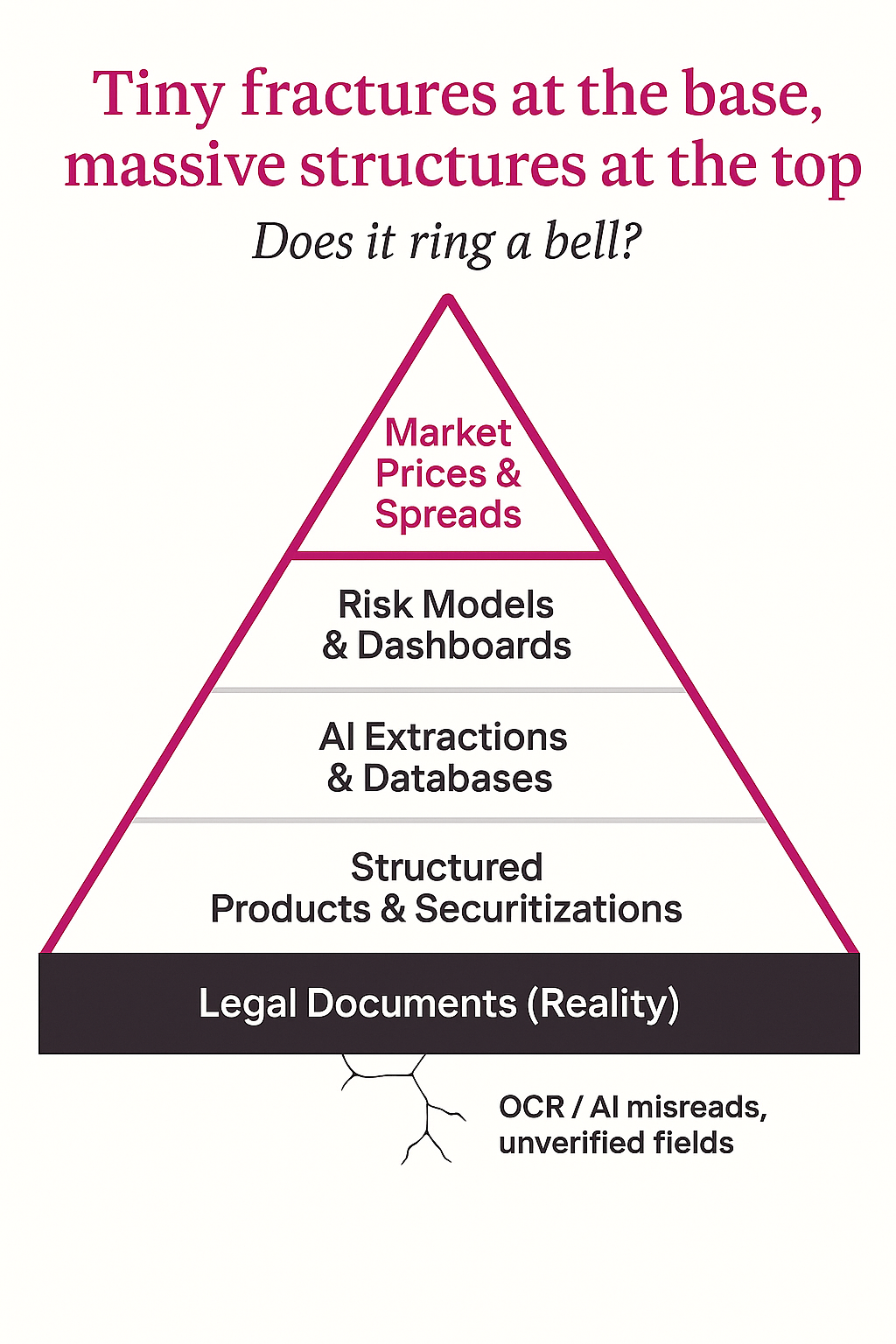
We are quietly plugging probabilistic, error-prone systems into the plumbing of private credit and structured finance, then building layers of leverage and valuation on top of outputs we assume are accurate but rarely re-verify. The risk isn’t a single spectacular blow-up; it’s a slow, invisible drift in how wrong the system can be before anyone notices.
Download our full report to learn what research says on our hypothesis:
For a summary of the 2022–2025 technical evidence behind this claim — including datasets, accuracy benchmarks, and QC case studies — see the Research Toggle below.
🔽 Click to Expand: Technical Research Notes
1. Evidence of Rapid AI-Driven Acceleration
Across 2022–2025, all major datasets confirm:
- AI adoption surged across private credit, leveraged loans, and fund finance.
- Straight-through processing (STP) jumped from ~5% → 50% for agents handling millions of notices per quarter.
- Analysts now complete tasks in minutes instead of hours, dramatically increasing deal throughput.
- Workflows shifted so that AI handles first-pass ingestion, and humans focus on synthesis, structuring, and credit committee preparation.
The acceleration is clear, measurable, and industry-wide.
2. Identified Accuracy Issues (OCR + NLP + GenAI)2.1. OCR / Numeric Errors
- Misread digits, decimal shifts, missing commas
- Wrong currency/date formats
- Table misalignment leading to incorrect EBITDA, add-backs, or borrowing-base calculations
2.2. Clause Misclassification
- NLP models mislabeling covenants
- Failure to detect carve-outs or exceptions
- Misinterpretation of incremental debt baskets, equity cures, non-GAAP adjustments
2.3. GenAI Contextual Errors
- Occasional hallucinated terms
- Summaries that omit crucial qualifiers hidden in definitions
- Non-deterministic interpretations of ambiguous phrasing
2.4. Compounding Error Rates
Even 95% field-level accuracy leads to frequent document-level errors once 20–50 fields are extracted.
3. Downstream Impact Pathways3.1. Underwriting
- Incorrect leverage because EBITDA or adjustments parsed wrong
- Misparsed collateral → mis-rated risk
- AI summaries introducing invented deal terms
- Potential breaches of investment guidelines due to misclassification
3.2. Monitoring
- Missed covenant breaches
- False breach alerts
- Incorrect interest reset dates
- Wrong compliance data flowing into monitoring dashboards
3.3. Reporting
- Portfolio dashboards pulling incorrect extracted fields
- LP reports misrepresenting risk or covenant compliance
- Regulatory communications based on misread notices
No systemic blow-up is publicly documented — but practitioners consistently warn that the risk grows as volume outpaces verification capacity.
4. Positive Counterexamples (Accuracy Has Kept Pace in Some Firms)
- Ontra: AI abstractions reviewed by trained specialists
- RiskSpan: 3-layer human-in-the-loop quality control
- S&P Global: All extracted fields link directly back to original doc/page
- DLA Piper: Lawyers independently validate every AI-generated summary
- Blooma: Human-verified “supervised document processing” for edge cases
These examples show that accuracy can scale — but only via deliberate investment in oversight and auditability.
5. Final Assessment of the Hypothesis
Supported, but partially.
- True: AI has dramatically accelerated PDF ingestion and increased throughput.
- True in part: Some firms’ accuracy checks have not scaled proportionally, creating higher downstream error risk.
- Not universal: Leading institutions with human-in-loop validation maintain high accuracy.
Working conclusion:
Private credit workflows now scale exponentially; accuracy controls often scale linearly. The gap is where operational and credit risk accumulates.
6. Methodological Notes
- Reviewed >40 industry sources (2023–2025): global lender surveys, vendor white papers, legal analyses, operations case studies.
- Evaluation structure: ingestion → extraction → classification → modeling → reporting.
- Separated automation at speed from automation with audit trails.
- Applied private-credit operational frameworks to categorize downstream effects.
Editor’s Note
This piece builds on our earlier parable on herding and rational imitation, “The Game Everyone Bought – Herd Behavior”, and is grounded in a longer technical research memo on AI, OCR, and private credit infrastructure.
Start from the orthodox view.
In classical finance, the Efficient Market Hypothesis (EMH) depends on two big assumptions:
- Relevant information flows into prices quickly.
- No one actor has such an advantage in processing that information that systematic mispricing can persist.
For years, the constraint wasn’t access to information, but the processing of it:
- 200-page credit agreements.
- Scanned PDFs full of covenants, carve-outs, and bespoke language.
- Agent notices, amendments, waivers, compliance certificates.
This is the messy, unglamorous sludge that actually underpins private credit, leveraged loans, and structured products.
AI arrives and says: I’ve got this.
- OCR to convert PDFs into text.
- NLP to classify clauses, pull out covenants, tag risk factors.
- Generative models to summarize “what really matters” for the deal.
At first, these tools are marketed as assistants:
“Let us do your data entry so you can focus on judgment.”
But structurally, once you have machines reading everything and spitting out structured fields, it’s one very short step to:
“This is the data. Everything downstream will treat it as ground truth.”
At that point, we’ve effectively delegated the first mile of truth to models whose error behaviour we don’t fully understand.
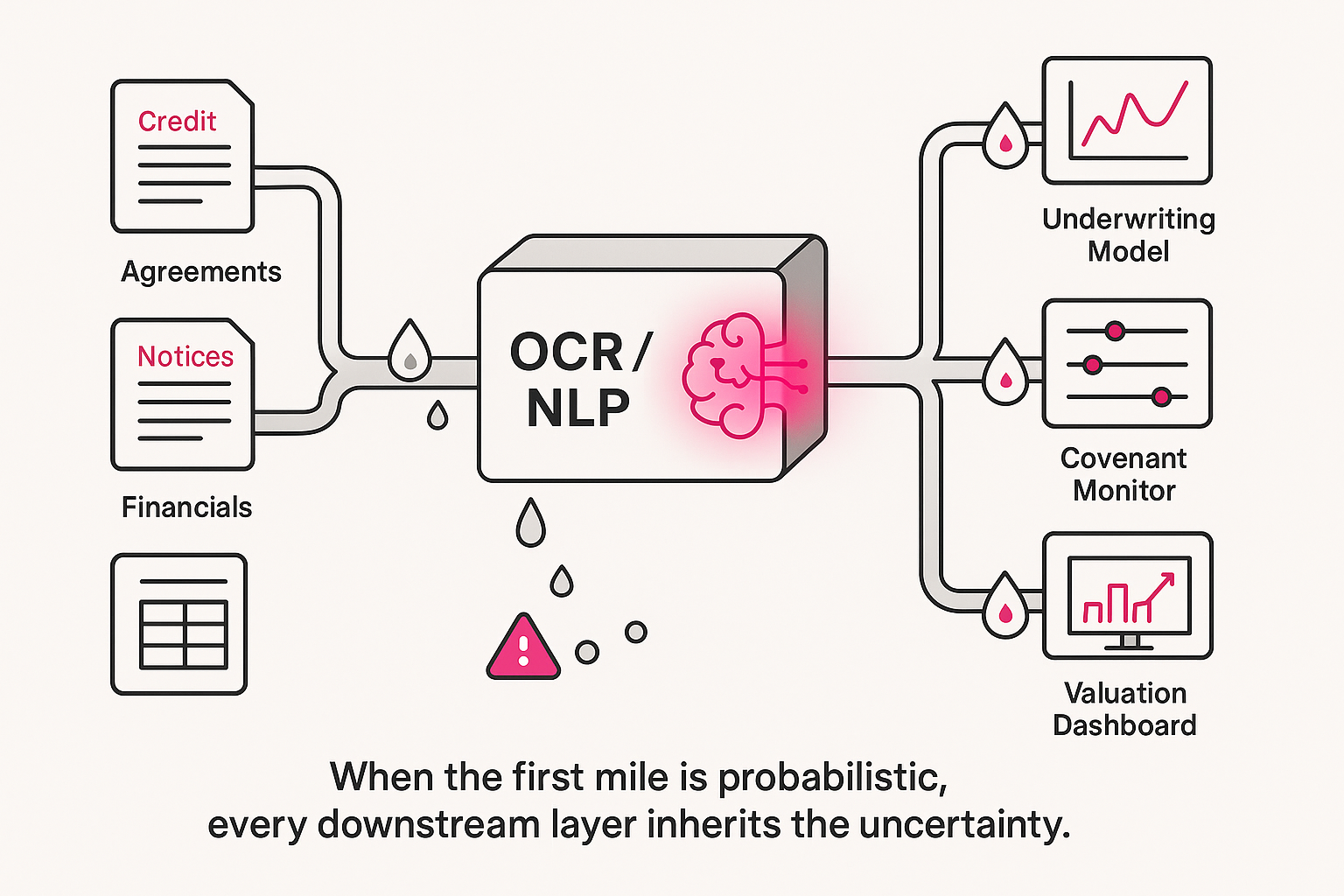
In a modern private credit workflow, AI can now feature in almost every stage of the pipeline:
- Origination & screening
- AI reads CIMs, websites, filings, and spits out a preliminary credit profile in minutes.
- Analysts see dashboards, not documents.
- Underwriting & documentation
- AI parses the draft credit agreement:
- tags covenants, baskets, events of default, collateral descriptions;
- extracts key thresholds into spreadsheets;
- flags “unusual” language compared to precedent.
- AI parses the draft credit agreement:
- Post-closing monitoring
- AI ingests quarterly financials and compliance certificates,
- calculates covenant ratios,
- flags potential breaches or early warning signs.
- Securitization and structured products
- Pools of loans are modeled based on attributes that may have originated from those AI extractions:
- leverage metrics,
- collateral type,
- seniority,
- covenant tightness.
- Pools of loans are modeled based on attributes that may have originated from those AI extractions:
- Valuation & secondary trading
- Risk models, spread curves, and pricing tools rely on those same attributes.
- “Market intelligence” dashboards build views of risk across portfolios and products, all of it absorbing upstream data.
Now overlay securitization, repo, and derivatives on top of that, and you’ve got a multi-layer tower resting on the assumption that the original field entries are correct.
But those fields now often come from:
- A scanner,
- A transformer model,
- And a workflow where a human might glance at some, but no one reads everything anymore.
The uncomfortable bit: AI is not a miracle; it is a probability distribution with a UX.
Even very good OCR / NLP systems behave like this:
- On clean, standard documents → error rates can be very low.
- On messy scans, unusual formatting, or bespoke language → error rates climb, and compounding begins.
Now imagine a single loan with, say, 30 data points pulled automatically from documents:
- facility size,
- maturities,
- margins and floors,
- leverage and coverage covenants,
- carve-outs and baskets,
- collateral descriptions, etc.
Even if each data point is 95% accurate, the chance that all 30 are correct is nowhere near 95%.
One wrong digit or mis-tagged clause is enough to pollute:
- a covenant monitor,
- a risk bucket,
- a valuation model.
Most of the time, somebody catches obvious nonsense:
- An EBITDA margin that’s clearly impossible.
- A “secured” tag on what everyone knows is subordinated paper.
But what about the small, plausible errors?
- A covenant threshold off by 0.25x.
- A basket misinterpreted in a way that gives a borrower just a bit more room.
- A definition subtly misread so “EBITDA” in the monitoring system is not quite what the contract says.
Each one of these is survivable. None triggers an immediate crisis.
The danger is accumulation:
- Across a single loan’s life,
- Across an entire portfolio,
- Across multiple managers and securitizations using similar tooling.
We might not get a Hollywood explosion, but perhaps a systematic drift could be a stone's throw away.
Your instinctive question is the right one:
“But how do we know mistakes haven’t already cascaded into deals, securitizations, valuations, trading? Maybe they’re already everywhere.”
The honest answer is: we don’t.
To prove a cascade, you would have to reconstruct, for a given deal or product:
- The original documents.
- The AI extractions (with model versions and confidence scores).
- Any manual edits or overrides.
- The models that ingested those fields.
- The decisions made (pricing, structure, inclusion in a pool).
- The resulting cash flows and losses.
And then show:
- “If this clause had been extracted correctly,
- the model would have been different,
- the decision would reasonably have changed,
- and the realized outcome would have been materially better.”
In practice:
- Logs are incomplete.
- Spreadsheets are overwritten.
- Models are tweaked constantly.
- People leave.
The trail dissolves. The only thing left is:
“In hindsight, that was a bad deal for lots of reasons.”
So we end up with a paradox:
- The more complex and automated the pipeline becomes,
- The more difficult it is to trace a specific error through it,
- The more tempting it is to assert that the system, in aggregate, must be “fine”.
Ignorance becomes a kind of comfort blanket.
If there were a massive AI-related blow-up, we’d at least see it.
The nightmare is something else:
a world where thousands of small AI-originated inaccuracies tilt decisions just enough to shift risk, returns, and valuations for years — and nobody ever convincingly connects the dots.
This is not “subprime 2.0”. But some rhymes are hard to ignore:
- Back then, we had complex products built on top of misunderstood loan pools.
- Today, we have complex products built on top of data pipelines whose error properties few people can fully explain.
The risk pathway looks roughly like this:
- Loan-level misrepresentation by accident
- A small but non-trivial fraction of loans have slightly wrong parameters in systems of record because of extraction issues.
- Individually, each error might move pricing or risk by a few basis points at most.
- Biased pooling and modeling
- If those errors are systematically directional (e.g., leverage understated, collateral overstated, covenants logged as a bit tighter than they are), then pools of loans look slightly safer than they are.
- Models trained or calibrated on those data sets inherit the same bias.
- Structured products and valuations
- Securitizations, risk-transfer trades, and marks on balance sheets all lean on these models.
- As long as macro conditions are benign, nothing “breaks”; yields look fine, losses stay within expected bands.
- Stress and unraveling
- A macro shock exposes that recoveries are weaker or defaults higher than models suggested.
Someone eventually digs deeper and realizes:
“Oh. We were feeding our models a more flattering version of the world than the legal documents actually describe.”
By then, though, cause and effect are hopelessly entangled with everything else: macro, policy, idiosyncratic management failures.
The narrative will be:
“Underwriting was too optimistic.”
The more precise narrative might be:
“Underwriting was partially built on error-ridden, AI-mediated abstractions nobody ever fully audited.”
But that sentence is unlikely to make it into many earnings calls.
To be fair, not everyone is reckless.
Some firms:
- Treat document AI as a formal model subject to model-risk governance.
- Keep humans in the loop to review every critical extraction.
- Store lineage: which clause, which page, which model version.
- Run periodic ground-truth audits (re-abstract a sample by hand and measure error).
In those shops, AI genuinely is an accelerator, not a hidden source of slippage.
The bigger issue is asymmetry:
- The incentives to adopt AI for speed and cost reduction are clear and immediate.
- The incentives to invest in painstaking validation, logging, and lineage are diffuse and long-term.
Will companies have the self-discipline to say:
“We’ll pay you 20 bps more in fees because your covenant extractions are rock-solid and fully auditable.”?
The market will absolutely reward:
- faster deal execution,
- lower operational headcount,
- and more product at scale.
So we get a familiar pattern:
- “Best-practice” firms try to do this right.
- A long tail of smaller or more aggressive players may happily adopt the tech without matching it with adequate controls.
- Standardization of vendor stacks means shared blind spots can spread across multiple institutions.
That’s where the systemic flavour creeps in. It’s not one villainous tool. It’s an ecosystem of shortcuts that collectively redefine what “true” even means in deal data.
If we took the risk seriously, the minimum viable sanity checklist would look something like:
- Document AI = Regulated Model
- Treat covenant extraction, OCR pipelines, and doc-NLP as models with:
- documented training data,
- validation reports,
- performance metrics by document type and quality.
- Treat covenant extraction, OCR pipelines, and doc-NLP as models with:
- Lineage by Design
- For every critical field, store:
- source file,
- page/section reference,
- extraction method and model version,
- any manual edits.
- Make it one click for a risk officer or auditor to go from a number on a dashboard back to the underlying clause.
- For every critical field, store:
- Routine Ground-Truth Audits
- Sample loans randomly.
- Re-do extractions manually.
- Publish internal “error maps”:
- Which fields fail most often?
- Under what conditions (scan quality, language, template)?
- Are errors directionally biased?
- Scenario Testing for Mis-measurement
- Don’t just stress macro variables.
- Stress data integrity:
- “What if leverage is systematically under-reported by 3–5%?”
- “What if X% of our ‘secured’ exposures are actually mis-tagged?”
- See how much that changes default and loss projections.
- Cultural Rule: Humans Own the Decisions
- Ownership of the decision implicitly means skepticism toward the pipeline that produced the inputs.
No analyst or committee should be able to say,
“That’s what the system said, so we assumed it was right.”
The fantasy version of the future is clean:
- AI slurps every PDF into a perfect database.
- Markets become more efficient.
- Risk is priced with microscopic precision.
The more realistic version is messier:
- We increasingly trade and securitize on top of abstractions,
- generated by systems that are impressive, but fallible,
- in an environment where no one has the time or incentive to fully re-read the underlying documents.
So the question for private credit and structured finance isn’t:
“Will AI improve profitability?”
It almost certainly will, in the short run.
The real question is:
“How much unmeasured, untraceable error are we willing to let into the core of our information infrastructure in exchange for that profitability?”
And if the answer is “we don’t know, but we’re doing it anyway,”
then the market isn’t operating under perfect information.
It’s operating under optimistic opacity, and pricing that as if it were truth.
Without optimistic opacity, we’re forced to ask:
Is any of this “productivity,” or just speed without truth?
